Lancer un algorithme d'IA sur les GPU
Introduction
Ce tutoriel a pour but d’exécuter un algorithme d’IA en python sur les clusters de calcul. Il se décompose en deux parties :
- lancer l’entraînement d’un modèle d’IA sur le cluster Bigfoot à l’aide d’un script de soumission
- lancer un Jupyter Notebook pour charger le modèle précédemment entraîné et l’exploiter via un job interactif
Pré-requis
- Être connecté à la frontale du cluster Bigfoot avec vos identifiants/mot de passe.
- Disposer d’une configuration ssh locale avec proxy transparent.
Ci cela n’est pas encore le cas, cliquez ici.
Linux bigfoot 5.10.0-14-amd64 #1 SMP Debian 5.10.113-1 (2022-04-29) x86_64
Welcome to Bigfoot cluster!
: :
.' :
_.-" :
_.-" '.
..__...____...-" :
: \_\ :
: .--" :
`.__/ .-" _ :
/ / ," ,- .'
(_)(`,(_,'L_,_____ ____....__ _.'
"' " """"""" """
GPU, GPU, GPU, ... ;-)
Type 'chandler' to get cluster status
Type 'recap.py' to get cluster properties
Sample OAR submissions:
# Get a A100 GPU and all associated cpu and memory resources:
oarsub -l /nodes=1/gpu=1 --project test -p "gpumodel='A100'" "nvidia-smi -L"
# Get a MIG partition of an A100 on a devel node, to make some tests
oarsub -l /nodes=1/gpu=1/migdevice=1 --project test -t devel "nvidia-smi -L"
Last login: Fri Jul 22 15:38:45 2022 from 129.88.178.43
login@bigfoot:~$
Lancer un entraînement
Dans cette partie, le but est de lancer l’entraînement d’un modèle d’intelligence artificielle sur le cluster de calcul Bigfoot via un script de soumission.
Environnement Python
Il faut dans un premier temps choisir son environnement de travail, qui doit comporter Python et les modules nécessaires. Pour la gestion des modules Python nous utiliserons conda.
Le script suivant permet de sourcer conda :
login@bigfoot:~$ source /applis/environments/conda.sh
Il suffit ensuite de choisir l’un des environnements conda disponible sur Bigfoot.
La commande suivante permet d’afficher les différents environnements disponibles :
login@bigfoot:~$ conda env list
# conda environments:
#
base * /applis/common/miniconda3
GPU /applis/common/miniconda3/envs/GPU
f-ced-gpu /applis/common/miniconda3/envs/f-ced-gpu
fidle /applis/common/miniconda3/envs/fidle
fidle-orig /applis/common/miniconda3/envs/fidle-orig
gpu_preprod /applis/common/miniconda3/envs/gpu_preprod
julia /applis/common/miniconda3/envs/julia
tensorflow1.x_py3_cuda10.1 /applis/common/miniconda3/envs/tensorflow1.x_py3_cuda10.1
tensorflow2.x_py3_cuda10 /applis/common/miniconda3/envs/tensorflow2.x_py3_cuda10
torch1.x_py3_cuda10 /applis/common/miniconda3/envs/torch1.x_py3_cuda10
torch1.x_py3_cuda92 /applis/common/miniconda3/envs/torch1.x_py3_cuda92
Dans notre exemple nous choisirons l’environnement GPU qui contient l’ensemble des modules nécessaires à l’utilisation de TensorFlow/Keras et de PyTorch.
La commande suivante permet d’afficher l’ensemble des modules disponibles dans un environnement donné.
login@bigfoot:~$ conda list -n GPU
Il est impossible d’ajouter un module à l’un des environnements proposés ci-dessus ou d’en modifier les versions.
Il est possible de créer son propre environnement si un module nécessaire n’est pas présent dans les environnements proposés. Pour plus d’informations concernant conda, rendez-vous sur cette page
Programme d’entraînement
Dans cet exemple, nous allons construire un réseau basique de classification du DataSet MNIST et l’entraîner.
Commençons par nous placer dans notre répertoire dédié sur le service de stockage Bettik, en remplaçant login par votre identifiant Perseus dans la commande suivante :
login@bigfoot:~$ cd /bettik/PROJECTS/project_name/login
Pour construire notre modèle, il faut créer un fichier train.py dans un répertoire tuto_ia/ contenant le code suivant :
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import Input
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.models import Model
from tensorflow.python.client import device_lib
print("GPUs Available: ", tf.config.experimental.list_physical_devices('GPU'))
(X_train, y_train), (X_test, y_test) = mnist.load_data()
num_train = X_train.shape[0]
img_height = X_train.shape[1]
img_width = X_train.shape[2]
X_train = X_train.reshape((num_train, img_width * img_height))
y_train = to_categorical(y_train, num_classes=10)
num_classes = 10
xi = Input(shape=(img_height*img_width,))
xo = Dense(num_classes)(xi)
yo = Activation('softmax')(xo)
model = Model(inputs=[xi], outputs=[yo])
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
callbacks = [tf.keras.callbacks.ModelCheckpoint(
filepath="best_model.h5",
monitor='val_accuracy',
mode='max',
save_best_only=True)]
model.fit(X_train, y_train,
batch_size=128,
epochs=20,
verbose=1,
validation_split=0.1,
callbacks=callbacks)
import torch
import torch.nn as nn
from torchvision import datasets, transforms
from tqdm import tqdm
import sys
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
self.linear = nn.Linear(in_features=28*28, out_features=10)
self.activation = nn.Softmax(dim=1)
def forward(self, x):
x = self.linear(x)
output = self.activation(x)
return output
def train(model, device, train_loader, val_loader, optimizer, epochs):
prev_acc = 0
for epoch in range(epochs):
print(f"Epoch {epoch+1}/{epochs}")
model.train()
for batch in tqdm(train_loader, file=sys.stdout):
X, Y = batch
X, Y = X.to(device), Y.to(device)
Y_pred = model(X)
optimizer.zero_grad()
loss = nn.CrossEntropyLoss()(Y_pred, Y)
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
accuracy = 0
for (X, Y) in val_loader:
X, Y = X.to(device), Y.to(device)
y_pred = model(X)
y_classes = torch.argmax(y_pred, dim=1)
accuracy += torch.sum(y_classes == Y)
accuracy = accuracy.item()/len(val_loader.dataset)
print(f"Validation accuracy : {accuracy}")
if accuracy > prev_acc:
torch.save(model, "best_model.pt")
prev_acc = accuracy
def main():
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
print(f"Used device : {device}")
transform=transforms.Compose([
transforms.ToTensor(),
torch.squeeze,
torch.flatten
])
dataset = datasets.MNIST("data", train=True, download=True, transform=transform)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=128)
model = Classifier().to(device)
adam = torch.optim.Adam(model.parameters(), lr=0.01)
train(model, device, train_loader, val_loader, adam, 20)
if __name__ == "__main__":
main()
Pour cela, vous pouvez soit créer le fichier train.py contenant ce code directement sur le cluster, soit le créer sur votre machine locale et le transférer sur votre espace Bettik avec la commande suivante en remplaçant login par votre identifiant Perseus :
login-local@machine-locale:~$ rsync -avxH train.py login@cargo.univ-grenoble-alpes.fr:/bettik/PROJECTS/project_name/login/tuto_ia/
Ce petit programme python crée le modèle de classification, l’entraîne sur un jeu de données d’entraînement en affichant son avancée sur la sortie standard, et sauvegarde le meilleur modèle dans le répertoire tuto_ia/.
Écrire un script d’exécution
Une fois le programme d’entraînement prêt, il faut écrire un script permettant de soumettre le lancement d’un job sur les machines de calcul.
Pour cela, il suffit de créer un fichier run_train.sh. Depuis le dossier où se situe votre fichier d’entrainement, il suffit d’exécuter la commande touch run_train.sh. Le fichier doit contenir le code suivant, en remplaçant login par votre identifiant Perseus et votre-projet par le nom de votre projet :
#!/bin/bash
#OAR -n Entrainement_tuto
#OAR -l /nodes=1/gpu=1,walltime=0:30:00
#OAR --stdout %jobid%.out
#OAR --stderr %jobid%.err
#OAR --project votre-projet
#OAR -p gpumodel='V100'
cd /bettik/PROJECTS/votre-projet/login/tuto_ia
source /applis/environments/cuda_env.sh bigfoot 10.2
source /applis/environments/conda.sh
conda activate GPU
python train.py
Ce script permet de préparer la requête OAR en spécifiant les ressources nécessaires, le projet concerné, ou encore la gestion de le sortie standard et de la sortie d’erreur.
Les détails des commandes OAR sont disponible ici
Il permet aussi de préparer les environnements conda et cuda nécessaires, et d’exécuter l’entraînement du modèle.
Soumettre le job
Nous allons maintenant pouvoir lancer le job sur les machines de calcul.
Dans un premier temps, il faut rendre le script exécutable avec la commande :
login@bigfoot:/bettik/PROJECTS/project_name/login/tuto_ia$ chmod +x run_train.sh
On peut alors soumettre son exécution via le gestionnaire de ressources avec la commande :
login@bigfoot:/bettik/PROJECTS/project_name/login/tuto_ia$ oarsub -S ./run_train.sh
[ADMISSION RULE] Modify resource description with type constraints
OAR_JOB_ID=18545
Le job a bien été soumis et un identifiant lui a été attribué, ici, OAR_JOB_ID=18545
Suivre l’exécution du job
On peut maintenant suivre l’avancement de notre job à l’aide de quelques commandes, en remplaçant login par votre identifiant Perseus :
login@bigfoot:/bettik/PROJECTS/project_name/login/tuto_ia$ oarstat -u login
Job id S User Duration System message
--------- - -------- ---------- ------------------------------------------------
18545 W login 0:00:00 R=32,W=0:30:0,J=B,N=Entrainement_tuto,P=votre-projet (Karma=0.014,quota_ok)
On voit que le job est en attente de ressources, en effet son status est à W pour Waiting. Il faudra donc patienter jusqu’à ce que la ressource demandée soit disponible.
En réessayant plus tard, on obtient :
login@bigfoot:/bettik/PROJECTS/project_name/login/tuto_ia$ oarstat -u login
Job id S User Duration System message
--------- - -------- ---------- ------------------------------------------------
18545 R login 0:00:13 R=32,W=0:30:0,J=B,N=Entrainement_tuto,P=votre-projet (Karma=0.014,quota_ok)
On voit que le job est lancé depuis 13 secondes, son status est à R pour Running.
L’évolution de la sortie standard de votre algorithme peut être suivie avec la commande suivante (en remplaçant 18545 par l’identifiant de votre job) :
login@bigfoot:/bettik/PROJECTS/project_name/login/tuto_ia$ tail -f 18545.out
Epoch 1/20
54000/54000 [==============================] - 2s 32us/sample - loss: 13.1363 - accuracy: 0.7976 - val_loss: 4.3970 - val_accuracy: 0.8908
Epoch 2/20
54000/54000 [==============================] - 1s 15us/sample - loss: 4.9776 - accuracy: 0.8747 - val_loss: 3.5514 - val_accuracy: 0.9047
Le modèle est maintenant entraîné, et il est sauvegardé dans le répertoire tuto_ia/.
Exploitation du modèle
Dans cette partie, le but est maintenant d’utiliser un job interactif afin de lancer un Jupyter Notebook sur le cluster et d’y acceder depuis le navigateur de votre machine locale pour charger le modèle et l’évaluer.
Lancement d’un job en interactif
Lancer un job en interactif permet d’accéder à la console d’un noeud de calcul pour y exécuter des commandes pas à pas. Une fois connecté à la frontal du cluster bigfoot, il suffit de lancer la commande suivante :
login@bigfoot:~$ oarsub -I -l /nodes=1/gpu=1,walltime=1:00:00 -p "gpumodel='V100'" --project votre-projet
[ADMISSION RULE] Modify resource description with type constraints
OAR_JOB_ID=18584
Interactive mode: waiting...
Starting...
Connect to OAR job 18584 via the node bigfoot5
login@bigfoot5:~$
Les arguments de cette commande sont très similaires à ceux renseignés précédemment dans le script de soumission du job, ils font exactement la même chose. Cependant, on ajoute ici l’option -I permettant de lancer le job en mode Interactif.
Dans notre exemple, le gestionnaire de ressources nous a connecté à bigfoot5.
Démarrer le serveur de Jupyter Notebook
Avant de lancer le Jupyter Notebook, il faut activer les environnements nécessaires via les commandes suivantes :
login@bigfoot5:~$ source /applis/environments/cuda_env.sh bigfoot 10.2
login@bigfoot5:~$ source /applis/environments/conda.sh
login@bigfoot5:~$ conda activate GPU
(GPU) login@bigfoot5:~$
Nous pouvons donc maintenant nous rendre dans le bon répertoire et lancer un Jupyter Notebook :
(GPU) login@bigfoot5:~$ cd /bettik/PROJECTS/project_name/login/tuto_ia/
(GPU) login@bigfoot5:/bettik/PROJECTS/project_name/login/tuto_ia$ jupyter notebook --no-browser --ip=0.0.0.0 &
[1] 23557
[I 10:25:56.965 NotebookApp] JupyterLab extension loaded from /applis/common/miniconda3/envs/GPU/lib/python3.7/site-packages/jupyterlab
[I 10:25:56.965 NotebookApp] JupyterLab application directory is /applis/common/miniconda3/envs/GPU/share/jupyter/lab
[I 10:25:56.968 NotebookApp] Serving notebooks from local directory: /home/login/tuto_ia
[I 10:25:56.968 NotebookApp] The Jupyter Notebook is running at:
[I 10:25:56.968 NotebookApp] http://(bigfoot5 or 127.0.0.1):8888/?token=452db8f89bfd209a9245662ed808f115cb666c1d15222cf3
[I 10:25:56.968 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 10:25:57.004 NotebookApp]
To access the notebook, open this file in a browser:
file:///home/login/.local/share/jupyter/runtime/nbserver-23557-open.html
Or copy and paste one of these URLs:
http://(bigfoot5 or 127.0.0.1):8888/?token=452db8f89bfd209a9245662ed808f115cb666c1d15222cf3
Le Jupyter Notebook est maintenant lancé en arrière-plan sur le cluster, la console dans laquelle le Notebook a été lancé est donc toujours accessible. Comme indiqué, le serveur du Notebook est accessible sur le port 8888 de bigfoot5
Pour stopper le serveur du Notebook à la fin de son utilisation, il suffira d’utiliser la commande : jupyter notebook stop
Accéder au Jupyter Notebook depuis sa machine locale
Pour accéder à ce serveur depuis votre machine locale, il faut créer un tunnel ssh entre votre machine et le cluster. Pour cela, il suffit de lancer sur votre machine locale la commande :
login-local@machine-locale:~$ ssh -fNL 8889:bigfoot5:8888 bigfoot.ciment
Il faut adapter cette commande à votre cas :
- remplacer 8889 par n’importe quel port disponible sur votre machine locale
- remplacer bigfoot5 par le nom de la machine sur laquelle le Notebook est lancé
- remplacer 8888 par le port spécifié par Jupyter lors du lancement du Notebook
- remplacer bigfoot.ciment par ce que vous avez défini pour l’accès transparent dans votre configuration ssh
Une fois cette commande exécutée, il faut accéder au Notebook depuis l’un des navigateurs de votre machine locale à l’adresse : http://localhost:8889, où 8889 est le port de votre machine locale choisi précédemment.
Lors de votre première connexion via un navigateur sur chaque cluster, il faudra copier-coller le token de connexion fournis par Jupyter lors du lancement du serveur :
[I 10:25:56.968 NotebookApp] The Jupyter Notebook is running at:
[I 10:25:56.968 NotebookApp] http://(bigfoot5 or 127.0.0.1):8888/?token=452db8f89bfd209a9245662ed808f115cb666c1d15222cf3
Ici, il faudra donc copier-coller 452db8f89bfd209a9245662ed808f115cb666c1d15222cf3, dans le champ token de l’interface graphique de Jupyter.
Exploitation du modèle
Il faut maintenant créer un Jupyter notebook via l’interface graphique de Jupyter :
En mettant le code suivant dans une cellule de code et en l’exécutant,
import tensorflow as tf
from tensorflow.python.client import device_lib
print("GPUs Available: ", tf.config.experimental.list_physical_devices("GPU"))
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
on doit obtenir :


Si la liste affichée n’est pas vide, c’est que TensorFlow a bien détecté le GPU et l’utilisera pour accélérer ses calculs dans toute la suite du code du Jupyter Notebook.
Si le type de device est cuda, c’est que PyTorch a bien détecté le GPU et l’utilisera pour accélérer ses calculs dans toute la suite du code du Jupyter Notebook.
Pour finir, le code ci-dessous permet de charger le modèle, de l’évaluer sur un jeu de test et de visualiser quelques prédictions.
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
%matplotlib inline
(X_train, y_train), (X_test, y_test) = mnist.load_data()
num_test = X_test.shape[0]
img_height = X_train.shape[1]
img_width = X_train.shape[2]
X_test = X_test.reshape((num_test, img_width * img_height))
y_test = to_categorical(y_test, num_classes=10)
model = tf.keras.models.load_model("best_model.h5")
loss, metric = model.evaluate(X_test, y_test, verbose=0)
y_pred = model(X_test)
for i in range(10):
plt.figure()
plt.imshow(X_test[i].reshape((img_width, img_height)))
plt.show()
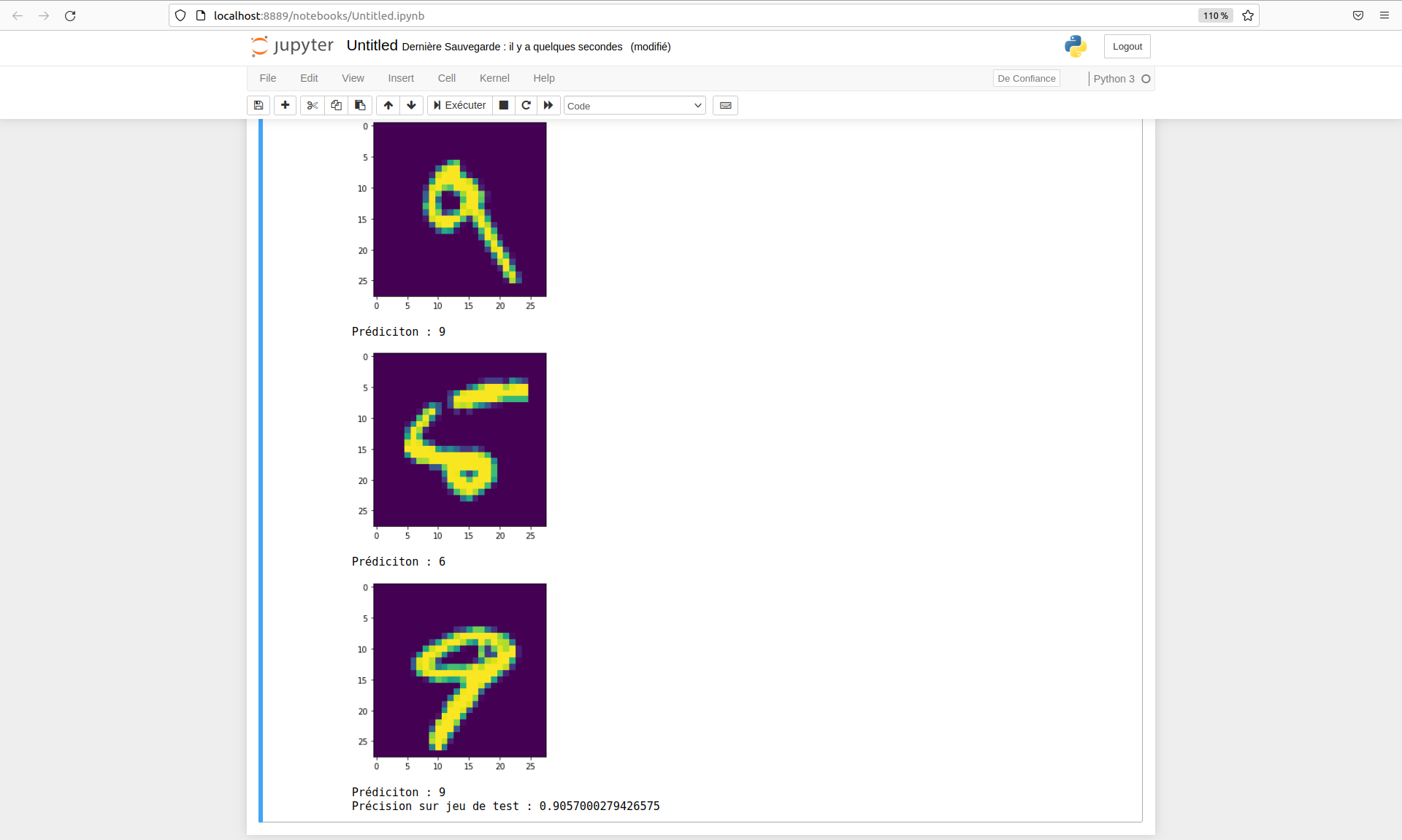
print(f"Prédiciton : {tf.math.argmax(y_pred[i])}")
print(f"Précision sur jeu de test : {metric}")
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
from train import Classifier
%matplotlib inline
transform=transforms.Compose([
transforms.ToTensor(),
torch.squeeze,
torch.flatten
])
dataset = datasets.MNIST("data", train=False, download=True, transform=transform)
model = torch.load("best_model.pt").to(device)
test_loader = torch.utils.data.DataLoader(dataset, batch_size=1)
model.eval()
accuracy = 0
with torch.no_grad():
for i, (X, Y) in enumerate(test_loader):
X, Y = X.to(device), Y.to(device)
y_pred = model(X)
y_classes = torch.argmax(y_pred, dim=1)
accuracy += torch.sum(y_classes == Y)
if i < 10:
plt.figure()
plt.imshow(X[0].reshape(28, 28).cpu())
plt.show()
print(f"Prédiction : {y_classes[0].item()}")
accuracy = accuracy.item()/len(test_loader.dataset)
print(f"Précision sur jeu de test : {accuracy}")
Voici un exemple de résultats obtenus :
Alternatives
Dans ce tutoriel, nous avons exécuté l’entraînement via un script de soumission et l’exploitation du modèle avec un Jupyter Notebook via un job interactif, cependant :
- il est aussi possible de réaliser l’entraînement via un job interactif, ce qui peut être utile pour tester votre programme d’entraînement sur un noeud de calcul réservé au développement.
- de même, il est possible de réaliser l’exploitation du modèle via un script de soumission. Cela peut être utile pour générer immédiatement des prédictions à la suite de l’entraînement. Le code à exécuter devra donc se trouver dans un fichier .py et son exécution devra être spécifiée dans le fichier run_train.sh.